
Open source changes that entirely. With a self-hosted voice pipeline, audio never leaves your infrastructure. There's no vendor attestation to chase, no shared cloud to audit, and no lock-in when model performance requirements evolve.
This guide covers exactly how to build one: infrastructure prerequisites, step-by-step build instructions, the parameters that separate a demo from a production tool, compliance architecture, and the mistakes that kill clinical adoption before go-live.
Key Takeaways
- Open source EHR voice assistants keep PHI entirely on-premises — no vendor BAAs, no cloud egress risk
- The core pipeline needs STT, an LLM reasoning layer, TTS, and FHIR/HL7 EHR integration
- FHIR mapping accuracy and latency management are the make-or-break factors for production readiness
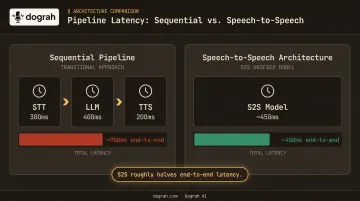
- Speech-to-Speech architectures roughly halve end-to-end latency compared to sequential STT→LLM→TTS pipelines
- Clinical adoption fails more often from poor workflow alignment than from technical deficiencies
What You Need Before Building
Open source doesn't mean zero prerequisites. Skipping infrastructure planning and EHR access prep leads to expensive rework mid-build.
System and Infrastructure Requirements
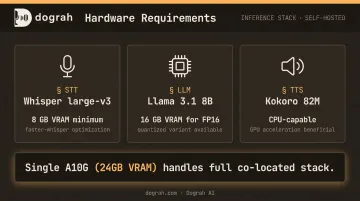
Running STT, LLM, and TTS inference locally with acceptable real-time latency requires real hardware. Rough minimums for a production stack:
- STT (Whisper large-v3): 8GB VRAM minimum; faster-whisper with CTranslate2 reduces this significantly
- LLM (Llama 3.1 8B): ~16GB VRAM for FP16 inference; quantized variants run on less
- TTS (Kokoro 82M): CPU-capable, but GPU acceleration drops latency substantially
- Total for a co-located stack: A single A10G or equivalent (24GB VRAM) handles all three comfortably
Containerized deployment via Docker simplifies this considerably. Dograh AI, for example, deploys its entire self-hosted voice agent stack via a single Docker command. First startup downloads all images in roughly 2–3 minutes, then the dashboard launches at localhost:3000. Docker version 20.10 or later is the only infrastructure prerequisite.
EHR Access and Integration Readiness
Before writing integration code, confirm:
- Target EHR exposes FHIR R4 APIs (Epic, Cerner/Oracle Health, athenahealth all do) or HL7 messaging for legacy systems
- You have sandbox credentials and access to the developer portal
- Patient identity matching data (MRN, encounter ID) is available for validation before any write operations
- API rate limits and write permissions are scoped for your use case
Compliance and Team Readiness
Once your infrastructure and EHR access are in place, the bottleneck usually shifts to people. You need three distinct skill sets: a voice/NLP engineer, a healthcare IT integration specialist, and a clinician subject matter expert. No single person bridges all three.
Teams using a pre-built OSS platform like Dograh AI (BSD 2-Clause license, self-hostable via Docker) can skip most of the underlying infrastructure wiring and move directly to clinical configuration — cutting weeks off the path from first deployment to first clinical test.
How to Build an Open Source AI Voice Assistant for EHR Systems
Step 1: Map Clinical Workflows and Define EHR Interaction Points
Never design the interface before the workflow. Start by auditing how clinicians actually document:
- Do they dictate after hours, type during visits, or use structured templates?
- Which specialties are in scope — primary care SOAP notes differ dramatically from ED triage or surgical dictation
- What's the acceptable interruption to clinical flow?
Then identify exactly which EHR data types the assistant will touch:
| Interaction Type | FHIR Resource | PHI Risk Level |
|---|---|---|
| Encounter notes | Encounter, DocumentReference | High |
| Diagnoses | Condition | High |
| Medications | MedicationRequest | High |
| Lab results (read) | Observation | High |
| Referrals | ServiceRequest | Medium |
Each resource carries different field requirements and write permissions. Knowing this before model selection prevents significant rework later.
Step 2: Select and Configure Your Open Source Model Stack
The standard pipeline — STT → LLM → TTS — works but stacks latency. Key model options:
- STT: Whisper large-v3 (OpenAI open weights) is the most widely deployed for healthcare; faster-whisper reduces inference time significantly. Voxtral from Mistral is an emerging alternative with strong multilingual performance
- LLM: Llama 3.1 8B Instruct runs locally with reasonable hardware; larger variants improve reasoning accuracy on complex clinical language
- TTS: Kokoro 82M is lightweight, fast, and deployable on CPU; Coqui XTTS handles voice cloning if consistent voice persona matters
One critical consideration: Speech-to-Speech (S2S) architectures using models like Gemini Flash Live or GPT-Realtime bypass the sequential pipeline entirely, roughly halving end-to-end latency. Dograh AI ships S2S orchestration across its full stack. At sub-600ms response times, the difference in feel is real: clinicians use tools that keep pace with them, not ones they wait on.
Generic STT models fail on drug names, abbreviations like "BID," "PRN," or "q.d.," and specialty terms at rates that are clinically dangerous. Medical vocabulary tuning is not optional. Dograh AI's STT keyword dictionary lets teams inject curated clinical vocabulary — drug names, department acronyms, clinician names — with elevated recognition priority. Add words weekly from actual call transcripts.
Step 3: Set Up Self-Hosted Infrastructure and Audio Pipeline
Run STT, LLM, and TTS in isolated containers. Key configuration decisions:
- Audio ingestion: Capture microphone input, apply noise filtering, and configure speaker diarization to separate clinician voice from patient voice — these are distinct streams with different handling requirements
- Streaming vs. batch: Clinicians cannot tolerate transcript lag during a live visit. Configure rolling buffers and partial transcript delivery for streaming inference, not batch processing. Streaming across STT, LLM, and TTS simultaneously is what keeps response times under 600ms
- Inter-service communication: Encrypt channels between containers; never pass raw audio or PHI transcript over unencrypted internal network segments
Step 4: Build the EHR Integration Layer
Map structured clinical output to the correct FHIR R4 resources:
- Symptoms and findings →
Observation - Diagnoses →
Condition - Prescriptions →
MedicationRequest - Visit documentation →
Encounter+DocumentReference
Patient identity validation must happen before any write. Linking a note to the wrong encounter is a clinical safety failure, not a bug. Require exact encounter ID validation — probabilistic matching is insufficient for write operations.
Build error handling from the start:
- Idempotent write operations prevent duplicate notes during retries
- Exponential backoff on failed API calls
- Transaction logging for every EHR write attempt, whether successful or failed
Dograh's webhook and API connectivity layer provides the integration infrastructure; the specific FHIR mapping logic for your EHR is built on top of that foundation.
Step 5: Add PHI Safeguards, Human Review, and Deploy
Security controls (non-negotiable):
- TLS 1.3 in transit for all audio and transcript streams
- AES-256 at rest for stored audio and generated notes
- Role-based access control — only authorized clinical roles initiate or view voice sessions
- Short-lived API tokens for EHR write operations
- Immutable audit logging across every STT transcription, LLM inference, and EHR write

Dograh AI includes all of the above in self-hosted deployments: RBAC, full per-turn audit logs with session ID, timestamps, model versions, and tool call records — no additional configuration required.
AI-generated notes must ship as editable drafts, not finalized records. Clinicians need to review and edit before any note is committed, with visible version history. This isn't a UX nicety — it's the primary driver of clinical trust. Adoption rises when clinicians retain clear control over what enters the permanent record.
Key Parameters That Determine Performance and Accuracy
Identical open source models can produce very different clinical outcomes depending on how four core parameters are tuned and configured.
Word Error Rate for Clinical Vocabulary
A dropped word like "no" in "no fever and nausea" inverts the documented clinical context. Research on ASR performance in clinical settings shows general-purpose models score meaningfully worse on medical terminology than their headline WER benchmarks suggest. Whisper achieves strong general English WER, but medical keyword error rates are meaningfully higher before custom tuning.
Benchmark medical keyword WER separately from general WER. The gap is where clinical risk lives.
End-to-End Latency
Latency accumulates across every pipeline stage. A sequential STT→LLM→TTS stack at 300ms + 400ms + 200ms totals nearly one full second before the clinician hears a response. That's enough to break conversational flow. S2S architectures eliminate two of those handoffs. Streaming partial transcripts reduces perceived lag further.
Key latency levers to account for during infrastructure planning:
- Pipeline architecture: S2S models cut handoffs; sequential STT→LLM→TTS stacks compound delay
- Streaming transcripts: Partial output reduces perceived lag even before full inference completes
- Defined thresholds: Set turn-gap limits before provisioning — Dograh AI targets under 885ms with a hard ceiling around 1,100ms
FHIR Mapping Accuracy
Incorrect field mapping — writing a diagnosis to the wrong FHIR resource, or linking a note to the wrong encounter — creates clinical risk and audit failures. This is where most EHR integration efforts break down during testing.
Deterministic matching (requiring exact encounter ID before writes) is slower but safe. Probabilistic matching improves throughput but introduces identity risk. For production clinical deployments, deterministic is the right default.
Model Inference Environment
| Environment | Latency | Compliance Posture | Cost |
|---|---|---|---|
| Shared cloud (third-party) | Low | High vendor overhead | Lower hardware cost |
| Self-hosted on-premises | Configurable | PHI stays local | Hardware investment |
| Private cloud (managed) | Low-medium | PHI stays in your cloud | Middle ground |

HHS guidance on HIPAA and cloud computing is clear: when a cloud provider processes PHI, they're a business associate. Self-hosted deployments eliminate that relationship entirely — and with it, the vendor compliance overhead that slows procurement in regulated healthcare environments.
Ensuring HIPAA Compliance and Data Sovereignty with Open Source
The core compliance advantage of open source is architectural: when models run on self-hosted infrastructure, PHI never leaves the organization's environment. There's no BAA to negotiate with a voice AI vendor, no SOC 2 attestation to review during procurement, and no third party holding raw clinical audio.
This distinction materially accelerates go-live timelines. Procurement cycles that take months with closed platforms can compress to weeks with self-hosted OSS.
Required technical safeguards (not optional hardening):
- TLS-in-transit for all audio and transcript streams
- AES-256-at-rest for stored audio files and generated notes
- RBAC tied to clinical roles
- Short-lived API tokens for EHR operations
- Immutable audit logs stored separately from application databases
Audit logging requirements: Every access, modification, and PHI write must log timestamp, user identity, action type, and session ID. Logs must be tamper-protected and survive application failures. This is what you present during a breach response or compliance audit.
Teams building from scratch must wire all of the above manually. Dograh AI's self-hosted deployment ships TLS 1.3, AES-256, RBAC, and per-turn audit logging as baseline infrastructure.
The BSD 2-Clause license gives healthcare organizations full freedom to add custom FHIR mapping, proprietary clinical NLP models, or any other modification — with no licensing obligations back to Dograh. In a self-hosted deployment, no audio, transcript, or PHI data is transmitted to Dograh's servers.
Common Mistakes When Building an AI Voice Assistant for EHR
Skipping clinical workflow mapping. The most common cause of clinician rejection. The assistant gets built around technical convenience rather than how documentation actually happens in a given department or specialty — it works in testing and fails in practice.
Using general-purpose STT without medical vocabulary tuning. Drug names, clinical abbreviations, and specialty terminology fail at high rates in untuned models. Developers miss this because they test with scripted phrases, not recordings of actual clinical conversations.
Treating EHR integration as a final step. Teams that integrate FHIR last discover mismatches between structured NLP output and EHR field requirements late in the project. Identity matching failures are clinical safety events — the integration layer deserves the same design rigor as the inference pipeline.
Ignoring latency until user testing. Architecture decisions around batch vs. streaming inference and pipeline design are extremely costly to reverse after deployment. Latency thresholds must be defined as hard requirements before infrastructure is provisioned, not discovered during testing.

Frequently Asked Questions
How is AI used in EHR?
AI is used in EHR systems for ambient documentation (converting clinical conversations into structured notes), voice-based data retrieval, automated coding assistance, and workflow triggers like referrals and follow-up scheduling. Each use case targets the same bottleneck: documentation time that pulls clinicians away from patients.
Can an open source voice assistant be HIPAA compliant?
Yes. When deployed on self-hosted infrastructure, all audio and PHI processing stays within the organization's environment. This eliminates data egress risk and vendor BAA requirements entirely, making self-hosted open source a stronger compliance fit than most closed alternatives.
What open source speech recognition models work best for healthcare?
Whisper (OpenAI open weights) is the most widely deployed OSS STT model for healthcare but requires custom vocabulary tuning for clinical terminology. Voxtral from Mistral is an emerging alternative with strong performance. Both require medical keyword benchmarking before production deployment; general WER scores don't reliably predict clinical accuracy.
How does a voice assistant integrate with an EHR system?
Integration uses FHIR R4 APIs for modern EHRs (Epic, Cerner, athenahealth all expose these) or HL7 messaging for legacy systems. Structured clinical entities extracted from the voice transcript are mapped to the correct FHIR resources and written back to the patient encounter after clinician review.
What is the difference between open source and closed voice AI platforms for EHR?
Closed platforms process audio on vendor-managed infrastructure, requiring vendor HIPAA/SOC2 compliance and BAA execution. Open source self-hosted platforms keep PHI entirely on-premises, give teams full model control, and remove vendor lock-in. The main trade-off is upfront infrastructure setup, which platforms like Dograh AI are designed to minimize.
How long does it take to build and deploy a voice assistant for EHR?
A basic voice-to-note pipeline using a pre-built OSS platform can be running in days. A production-grade deployment with FHIR integration, PHI controls, and clinical workflow alignment typically takes several weeks to months, depending on EHR complexity and the specialty tuning required.


