
Two factors are driving teams toward self-hosted TTS. First, cost: ElevenLabs charges $0.05–$0.10 per 1,000 characters, and those fees stack fast at scale. Second, data control: for healthcare, fintech, legal, and enterprise teams, sending audio and transcripts to a third-party API isn't just expensive — it's a compliance risk. McKinsey found that 60% of decision makers reported lower implementation costs with open-source AI compared to proprietary alternatives.
This article evaluates six leading open-source TTS models based on speech quality, licensing, multilingual support, and production readiness — so you can match the right model to your deployment context.
Key Takeaways
- Top open-source TTS models in 2026: Kokoro, Chatterbox-Turbo, Higgs Audio V2, Orpheus, Fish Audio S2 Pro, and Dia2
- Apache 2.0 and MIT licenses are safe for commercial use; Fish Audio S2 Pro requires a paid commercial license
- Best for edge/low-cost deployments: Kokoro (82M params, Apache 2.0)
- Best for voice agents: Chatterbox-Turbo (MIT) or Orpheus (Apache 2.0)
- Best overall naturalness: Higgs Audio V2 (~5.8B, Apache 2.0)
- All can be self-hosted with no third-party API keys — critical for HIPAA, GDPR, and regulated industries
What Are Open-Source AI Voice Generators?
Open-source AI voice generators are TTS (text-to-speech) models whose weights and/or code are publicly available, letting teams self-host them on their own infrastructure — unlike proprietary APIs like ElevenLabs or OpenAI TTS, which process your text and audio on their servers. Before picking a model, though, there's a licensing reality most teams learn the hard way.
License Types Matter More Than You Think
Not all "open-source" TTS models are equally free to use. The practical split:
- Apache 2.0 / MIT — fully free for commercial use, auditable, modifiable, no negotiation required
- Restricted open-weight licenses (like Fish Audio's Research License) — weights are accessible, but commercial use requires a paid license from the vendor
- Coqui Public Model License — open for some uses, restricted for others; always read before deploying
Production teams routinely discover this distinction too late. A model that's free to experiment with can require a commercial agreement before shipping.
TTS Is One Layer in a Larger Pipeline
TTS alone doesn't make a voice agent. A complete voice AI system combines:
- STT (speech-to-text) — transcribes caller audio, for example Whisper or Deepgram
- LLM — generates the response; Llama, GPT-4o, and Gemini are common choices
- TTS — converts the response back to audio

Orchestrating these three layers in real time — with low latency, proper streaming, and no data leakage — is where most of the engineering complexity lives. Dograh AI (open-source under BSD 2-Clause) handles exactly this orchestration — connecting locally hosted TTS models like Kokoro and Chatterbox with STT and LLM components into a complete voice agent pipeline, without routing any data through third-party APIs.
Best Open-Source AI Voice Generators in 2026
Models below were selected based on active development status, license permissiveness, speech naturalness, multilingual support, voice cloning capability, and production readiness.
Kokoro (by Hexgrad)
Kokoro is an indie-developed, 82M-parameter TTS model released under Apache 2.0. It's built on StyleTTS 2, avoids encoder or diffusion architectures, and produces natural-sounding English speech at a fraction of the compute cost of larger models. Teams that need fast, cost-efficient voice synthesis on modest hardware will find little reason to look elsewhere first.
Its small footprint means it runs on CPUs and consumer GPUs without specialized infrastructure. It ranks consistently well on community naturalness evaluations, and its Apache 2.0 license removes any commercial friction.
| Attribute | Details |
|---|---|
| License / Parameters | Apache 2.0 / 82M |
| Language Support | English-primary (limited multilingual) |
| Best For | Edge deployment, low-cost production TTS, embedded voice applications |
Chatterbox-Turbo (by Resemble AI)
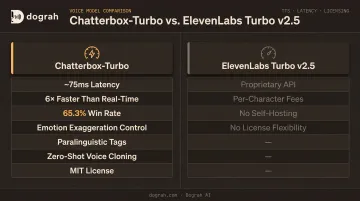
Chatterbox-Turbo is a 350M-parameter TTS model from Resemble AI, released under MIT. It's built for production-grade low-latency generation — reporting ~75ms latency and up to 6x faster than real-time on a single GPU, using a single-step distilled decoder that reduces generation from 10 steps to 1.
Resemble reports a 65.3% win rate against ElevenLabs Turbo v2.5 in Podonos head-to-head evaluations. Beyond speed, it's the first open-source TTS model with emotion exaggeration control — dial intensity up or down — and supports paralinguistic tags like [laugh], [cough], [sigh], [whisper], and [gasp]. Zero-shot voice cloning from a short reference clip is also supported.
A multilingual variant (Chatterbox-Multilingual, ~500M, 23+ languages) extends coverage for global deployments.
| Attribute | Details |
|---|---|
| License / Parameters | MIT / ~350M |
| Language Support | English (multilingual variant for 23+ languages) |
| Best For | Voice agents, real-time conversational AI, expressive character voice |
Higgs Audio V2 (by BosonAI)
Higgs Audio V2 is the highest-fidelity model on this list. It combines a 3.6B LLM backbone (Llama-3.2-3B) with a 2.2B Dual-FFN audio processing layer — roughly 5.8B parameters total — pretrained on over 10 million hours of audio under Apache 2.0.
A Dual-FFN layer adds audio-specific processing on top of the LLM backbone, and a unified audio tokenizer trained from scratch encodes semantic and acoustic features at 25fps. On EmergentTTS-Eval, it achieves a 75.7% win rate on Emotions and 55.7% on Questions over GPT-4o-mini-TTS.
The trade-off is hardware: BosonAI recommends a GPU with at least 24GB of VRAM for efficient inference (RTX 4090 or equivalent for the 3B audio generation model). Skip this one for edge deployments; the hardware requirements make it the right call only when output quality comes first.
Note: the Higgs GitHub lists Apache 2.0, while the Hugging Face model card shows "other" as the license field. Verify directly before deploying commercially.
| Attribute | Details |
|---|---|
| License / Parameters | Apache 2.0 (verify) / ~5.8B |
| Language Support | Multilingual with voice cloning |
| Best For | Premium audiobooks, high-quality brand voice, SOTA naturalness |
Orpheus (by Canopy AI)
Orpheus is a Llama-based TTS family from Canopy AI, released under Apache 2.0, offering models from 150M to 3B parameters. The 3B checkpoint is currently available, with smaller variants (1B, 400M, 150M) on the development roadmap. It was trained on 100K+ hours of English speech.
Orpheus is flexible enough to cover most deployment contexts without model-swapping. Key capabilities:
- Streaming latency of ~200ms, reducible to ~100ms with input streaming
- Zero-shot voice cloning from a reference clip
- Guided emotion control via tags: laugh, chuckle, sigh, cough, groan, yawn, gasp
- Real-time audio streaming built in
A multilingual research preview launched in April 2025, extending the model family to include Chinese, Hindi, Korean, and Spanish variants — making it one of the stronger open-source options for teams needing consistent voice output across geographies.
| Attribute | Details |
|---|---|
| License / Parameters | Apache 2.0 / 150M–3B (configurable) |
| Language Support | English + multilingual family (Chinese, Hindi, Korean, Spanish) |
| Best For | Multi-environment deployments, real-time streaming, multilingual voice agents |
Fish Audio S2 Pro (by Fish Audio)
Fish Audio S2 Pro is the benchmark leader on this list. Its Dual-Autoregressive architecture pairs a slow 4B AR model for temporal structure with a fast 400M AR for fine acoustic detail, trained on 10M+ hours of multilingual audio across 80+ languages.
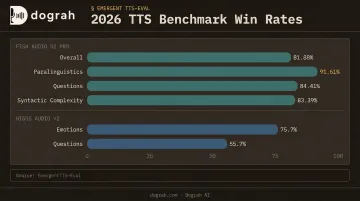
On EmergentTTS-Eval, it achieves an 81.88% overall win rate — outperforming ElevenLabs, Seed-TTS, and Google. Benchmark breakdown:
- Paralinguistics: 91.61% win rate
- Questions: 84.41% win rate
- Syntactic complexity: 83.39% win rate
Latency on a single NVIDIA H200 is approximately 100ms TTFA with a 0.195 real-time factor. Emotion control uses free-form natural-language descriptions embedded at specific word positions — no fixed tags required.
License caveat: Fish Audio S2 Pro uses the Fish Audio Research License. Commercial use of the open-weight model requires a paid license from Fish Audio. Free use applies to research only. This is a hard blocker for production deployments that need permissive licensing.
| Attribute | Details |
|---|---|
| License / Parameters | Research license (commercial license required) / Dual-AR ~4B + ~400M |
| Language Support | 80+ languages with cross-lingual voice cloning |
| Best For | Multilingual production TTS, brand voice cloning, high-accuracy applications |
Dia2 (by Nari Labs)
Dia2 is purpose-built for dialogue. Released under Apache 2.0 by Nari Labs in 1B and 2B parameter variants, it interprets [S1] and [S2] speaker tags to generate realistic two-speaker conversations — including nonverbal sounds like laughter, coughing, and sighing — rather than treating multi-speaker output as a secondary feature.
Its streaming architecture begins synthesizing audio from the first few input tokens, which cuts turn latency meaningfully in back-and-forth dialogue scenarios. Zero-shot voice cloning via reference audio upload is supported. The main constraint: English-only generation, capped at 2 minutes per output.
For podcasts, multi-speaker audiobooks, game dialogue, and conversational agent simulations, Dia2 has no close Apache-licensed competitor.
| Attribute | Details |
|---|---|
| License / Parameters | Apache 2.0 / 1B or 2B |
| Language Support | English only (2-minute max) |
| Best For | Dialogue generation, podcasts, multi-speaker audiobooks, conversational agents |
How We Chose the Best Open-Source AI Voice Generators
Evaluation Criteria
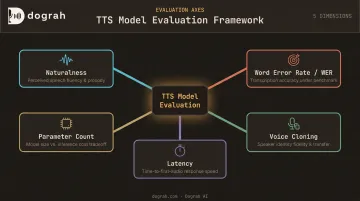
Model selection focused on five primary axes:
- Naturalness — assessed via community leaderboards including the TTS Arena V2 on Hugging Face, which uses side-by-side human preference voting
- Word Error Rate (WER) — accuracy of synthesized speech when re-transcribed; best validated using Whisper on a representative production text sample
- Voice cloning capability: zero-shot speaker replication from short reference audio
- Latency — time-to-first-audio for real-time deployment use cases
- Parameter count — hardware cost and edge deployment viability
Secondary factors included multilingual support, active development status, and license permissibility.
Common Mistakes to Avoid
The most common mistake is optimizing purely for naturalness scores while overlooking license type. TTS Arena scores reflect general English speech — not specialized domains like medical terminology, financial scripting, or legal language. Always benchmark candidate models on your own domain-specific text before finalizing.
A few practical guidelines:
- Apache 2.0 and MIT are safe for commercial deployment without legal review
- Fish Audio S2 Pro requires vendor negotiation before production use
- Higgs Audio V2's license field conflict (Apache 2.0 on GitHub vs. "other" on Hugging Face) requires direct confirmation before use
- WER should be measured on your actual production prompts — generic test sets Use Whisper on your actual production prompts — generic test sets won't surface domain-specific failure modes
Conclusion
In 2026, open-source TTS delivers production-grade quality. Kokoro, Chatterbox-Turbo, Higgs Audio V2, Orpheus, Fish Audio S2 Pro, and Dia2 each solve distinct production problems. The right choice comes down to three factors: deployment environment, language requirements, and license constraints.
That said, for teams building full voice agents rather than standalone audio files, TTS is one layer in a three-part stack. Integrating it with STT, an LLM, and telephony requires orchestration that handles streaming, latency budgets, and data routing correctly.
Dograh AI — open-source under BSD 2-Clause — supports locally hosted TTS models including Kokoro and Chatterbox alongside Whisper STT and any LLM. All audio and transcript data stays within your own infrastructure, with no vendor lock-in and no third-party API exposure.
If you want to deploy a production-ready voice agent using open-source TTS in under 2 minutes, the Dograh AI GitHub repository is the fastest starting point.
Frequently Asked Questions
Is there a completely free AI voice generator?
Yes. Kokoro (Apache 2.0), Chatterbox-Turbo (MIT), Higgs Audio V2 (Apache 2.0), Orpheus (Apache 2.0), and Dia2 (Apache 2.0) are all free for commercial use. "Free" covers the model weights and code — self-hosting requires compute infrastructure, and Fish Audio S2 Pro requires a paid commercial license from Fish Audio for production use.
Is there an open-source voice assistant?
Open-source voice assistants combine STT, LLM, and TTS into an orchestrated pipeline. Dograh AI (BSD 2-Clause, self-hostable) and Mycroft AI are purpose-built frameworks for this. The TTS models above — Kokoro, Chatterbox, Orpheus — are components that plug into these broader systems rather than complete assistants on their own.
Is there an AI I can have a real-time voice conversation with?
Real-time voice conversation requires a Speech-to-Speech pipeline combining STT, LLM, and TTS. Dograh AI supports full S2S orchestration using Gemini Flash Live and OpenAI GPT-Realtime-2, roughly halving end-to-end latency — or you can assemble a fully open-source stack with Whisper (STT), Llama (LLM), and Kokoro or Chatterbox (TTS).
What is the difference between voice AI and conversational AI?
Conversational AI handles natural language understanding and response generation — the reasoning layer. Voice AI covers the audio layer: STT to understand spoken input and TTS to produce spoken output. A voice AI agent combines both: conversational AI for decision-making, and voice AI models to handle the spoken interface.
What is the best open-source TTS model for production use in 2026?
The right pick depends on your use case:
- Real-time voice agents: Chatterbox-Turbo (MIT, ~75ms latency, voice cloning)
- Premium audio content: Higgs Audio V2 — best naturalness, but GPU-heavy
- Multi-tier deployments: Orpheus — most flexible across hardware tiers
- Edge or cost-sensitive: Kokoro — lowest resource requirements


