
Introduction
Here's the frustration most voice AI builders hit in 2026: you pick a "low-code" framework like LiveKit or Pipecat to avoid heavy engineering work, then spend weeks writing custom orchestration code for turn-taking, interruption handling, and telephony integration anyway.
So you consider a managed platform like Vapi or Retell — until you see the pricing model, realize your call data flows through their infrastructure, and discover that switching later costs more than starting from scratch. One path demands engineering time. The other trades control for vendor dependency.
This guide breaks down what low overhead actually means at the architecture level, how to evaluate open source voice AI platforms against that standard, which deployment models are worth your attention, and the specific techniques that cut latency and cost in production.
Key Takeaways
- "Low-code" frameworks like LiveKit and Pipecat still require custom orchestration code for interruption handling, turn-taking, and telephony
- A truly low-overhead platform ships with a visual workflow builder, pre-built telephony, and local model support — no glue code needed
- Self-hosted OSS deployments skip vendor compliance reviews entirely: no HIPAA BAA, GDPR DPA, or SOC 2 evaluation required
- Picking the wrong deployment model for your team profile adds overhead instead of cutting it
- Speech-to-Speech orchestration and hybrid pre-recorded + TTS are the two biggest production levers for latency and cost
Why "Low-Code" Voice AI Frameworks Still Require Heavy Custom Code
The Promise vs. Reality Gap
LiveKit and Pipecat handle real things well: audio transport, basic pipeline wiring, and STT/LLM/TTS connections. But their own documentation reveals the problem. LiveKit's turn detection docs state that turn detection and interruption management are "essential to good voice AI" — meaning the framework exposes the problem, not the solution.
The GitHub issue tracker confirms it. In September 2025, one LiveKit issue reported that interruption settings made the agent "too sensitive," causing it to cut off users speaking slowly. Another reported the agent going silent while still marked as "speaking" — a bug that appeared more often on live phone calls than in local testing. These aren't edge cases. They're the exact failure modes production voice agents hit.
Pipecat frames the same challenge directly: a brief pause does not always mean the user is finished, so teams must combine VAD, transcription, and turn-detection models and tune when to respond. Telephony deployment adds another layer: provider-specific call control and state handling that each requires its own adapter logic. That complexity feeds directly into the API chain problem.
The API Chain Problem
The compounding effect is concrete:
- Sales teams wait days for engineering to push a prompt change
- A new objection-handling path requires a full deployment cycle
- Each iteration delay widens the gap against teams who can test and ship in hours
The fix isn't just switching to open source — it's finding a platform that removes custom orchestration overhead while keeping full control over models, data, and where everything runs.
What a Truly Low-Overhead Voice AI Platform Looks Like
The Core Stack: STT, LLM, and TTS (and Where Overhead Hides)
The classic three-layer pipeline runs like this: STT converts caller audio to text, an LLM reasons over that text and generates a response, and TTS converts the response back to audio. When each layer runs as a separate API service, latency accumulates at every boundary and failure modes multiply.
Speech-to-Speech (S2S) orchestration changes this architecture fundamentally. By keeping voice and reasoning in a shared runtime — using models like OpenAI GPT-4o Realtime or Gemini Flash Live — the pipeline collapses. OpenAI reported GPT-4o responding to audio in as little as 232ms minimum, averaging 320ms — approaching human conversation timing.
A cascaded API chain can't get close to that.
At the platform level, low overhead means four things:
- Drag-and-drop workflow builder that replaces custom orchestration code for branching logic, conditions, and multi-agent flows
- Pre-built telephony integrations that eliminate manual SIP configuration and adapter development
- API key rotation across LLM, STT, and TTS providers to avoid rate ceiling hits during peak volume
- Configurable post-call analytics that automate sentiment checks and adherence scoring without manual QA
Open Source Model Support: Running Locally Without Compromise
The 2026 open model landscape makes fully on-premise voice stacks viable. Here's what's available at each layer:
| Layer | Models | License | |-------|--------|---------|| | STT | Whisper (39M–1.55B params, 96 languages, 680K hours training), Canary-1B-v2 (25 European languages), Voxtral (3B and 24B, Apache-2.0) | MIT / CC-BY-4.0 / Apache-2.0 | | LLM | Llama 4 Scout (10M-token context, runs on single H100), Qwen3/Qwen3.5 (262K context, Apache-2.0) | Custom community / Apache-2.0 | | TTS | Kokoro-82M (Apache-2.0, 8 languages, 54 voices), Coqui TTS (MPL-2.0, XTTSv2 supports 16 languages), Chatterbox (MIT, 23 languages) | Apache-2.0 / MPL-2.0 / MIT |
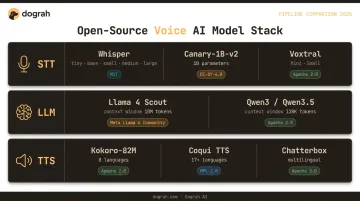
The tradeoff between cloud APIs and local models comes down to volume and compliance:
- Cloud API models — lower infrastructure cost, higher per-call cost, data leaves the environment
- Locally hosted models — upfront GPU investment, zero per-call API fees at scale, full data sovereignty
For regulated industries or high call volumes, local models win on both dimensions once volume crosses the break-even point. That's where platform architecture becomes the deciding factor.
Dograh AI is built as the self-hostable open source alternative to Vapi and Retell (BSD 2-Clause license, Docker deployment). It supports all major locally hosted STT, LLM, and TTS models through a bring-your-own-model architecture, paired with a visual workflow builder that eliminates custom orchestration code. A working agent deploys in under 2 minutes: open the dashboard, choose call type, name the bot, describe the use case, and it's live.
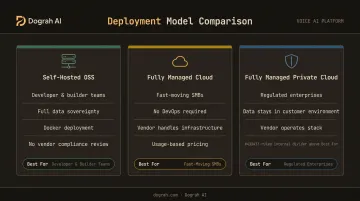
Deployment Models: Self-Hosted OSS, Fully Managed Cloud, and Private Cloud
Three models cover the full range of team profiles and compliance requirements. Choosing the wrong one doesn't just cost money — it creates operational drag that undermines the efficiency gains you deployed voice AI to achieve.
Self-Hosted OSS
Deploy via Docker on your own infrastructure. Call recordings, transcripts, and PII never leave your environment. Vendor compliance evaluations — HIPAA BAA negotiation, GDPR DPA review, SOC 2 assessment — are eliminated entirely because there's no vendor in the data path.
Dograh AI's self-hosted deployment ships with TLS 1.3 in transit, AES-256 at rest, RBAC, and full audit logging natively. A developer with basic Docker experience can run the platform with a single command; first startup takes 2–3 minutes to pull images.
Best for: Developer and builder teams, regulated organizations with internal DevOps capacity, air-gapped or classified environments.
Requires: Internal infrastructure management and DevOps capacity.
Fully Managed Cloud
The vendor runs the infrastructure. Fastest path to production — no infrastructure overhead, no DevOps requirement. Suitable for non-regulated use cases or teams that need to move quickly without internal engineering resources.
The tradeoff: call data passes through the vendor's environment, which reintroduces compliance evaluation requirements. Usage-based pricing also requires careful modeling before committing to higher volumes.
Best for: Fast-moving SMBs without dedicated DevOps, non-regulated use cases, early-stage pilots.
Requires: Vendor compliance review (GDPR DPA, SOC 2, etc.) and usage cost modeling before scaling.
Fully Managed Private Cloud
The vendor builds and operates the entire voice AI infrastructure inside the customer's own cloud environment. Data sovereignty is maintained — nothing leaves the customer's infrastructure — while the vendor handles all operational overhead: orchestration, deployments, upgrades, monitoring, and reliability.
This is the model Dograh AI uses for regulated enterprise engagements across healthcare, fintech, legal, and defense. The customer gets compliance without engineering burden.
Best for: Regulated enterprises (healthcare, financial services, government, GDPR regions) that need data sovereignty but lack the internal capacity to operate the stack themselves.
Requires: Vendor engagement and scoping; no internal DevOps required once deployed.
Choosing the Right Model
The table below maps team profile to deployment model. If your situation doesn't fit neatly, the self-hosted OSS path is always reversible — you can migrate to managed private cloud later without re-architecting.
Quick-Reference Framework
| Team Profile | Deployment Model |
|---|---|
| Developer / builder team with DevOps | Self-hosted OSS |
| Fast-moving SMB, no DevOps | Fully managed cloud |
| Regulated enterprise (HIPAA, GDPR, fintech, legal) | Fully managed private cloud |
Latency and Cost Optimization Techniques for Production Voice AI
Architecture-Level Latency Levers
Three changes move the needle most in production:
- Adopt S2S orchestration — removes the STT/LLM/TTS API boundary overhead. Dograh AI ships S2S across the full stack using Gemini Flash Live and OpenAI GPT-Realtime-2, roughly halving end-to-end latency versus the classic cascaded pipeline
- Deploy telephony infrastructure per geographic region — running services in the same region as callers reduces network round-trip time
- Implement API key rotation — prevents rate-limit bottlenecks during peak call volume by distributing load across multiple provider keys for LLM, STT, and TTS
Hybrid Pre-Recorded + TTS: Cost and Quality Together
For high-frequency, predictable utterances — greetings, confirmations, standard objection responses — real human voice recordings sound more natural than any TTS model and cost a fraction of per-character API pricing at scale. TTS handles dynamic content as the fallback.
The challenge has always been voice consistency: pre-recorded clips and TTS-generated speech sound like different people. Dograh AI solves this with an industry-first implementation where both the pre-recorded clips and the TTS fallback use the same cloned voice, making the transition seamless.
The result: up to 3× cost reduction and 2× better conversion rates on outbound calls.
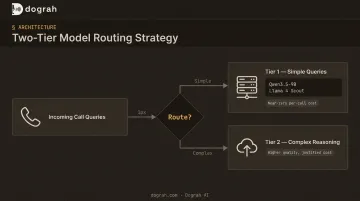
Model Routing as a Cost Lever
Tier-1 queries — simple confirmations, FAQ responses, routing decisions — can run through smaller, faster locally hosted LLMs at near-zero per-call cost. Complex reasoning, escalations, and edge cases route to larger cloud models where quality justifies the cost.
Platforms that support bring-your-own-model (BYOM) give teams the flexibility to optimize this mix. Strong tier-1 candidates for most voice use cases include:
- Qwen3.5-9B — 262K context window, Apache-2.0 license, fast inference on modest hardware
- Llama 4 Scout — 10M context window, runs on a single H100, handles longer conversational threads without model switching
Data Sovereignty and Compliance in Self-Hosted Voice AI
Self-hosted voice AI changes the compliance calculus at procurement. When call recordings, transcripts, and PII never leave your own infrastructure, the vendor compliance evaluation process disappears from the critical path.
No HIPAA BAA negotiation. No GDPR DPA review. No SOC 2 assessment for a platform vendor. That removes a procurement bottleneck that can delay go-live by weeks in regulated industries.
The Amazon/Alexa case from 2023 — where the FTC and DOJ charged Amazon with retaining children's voice recordings, resulting in a proposed $25M penalty — illustrates what voice data retention obligations look like when they're someone else's problem. Self-hosting makes them yours, but fully within your control.
Internal obligations that remain regardless of deployment model:
- Encryption at rest (AES-256) and in transit (TLS 1.3)
- Role-based access controls on recordings and transcripts
- Data retention policies with defined deletion schedules
- Audit logging for all data access and processing events
These are internal controls — not vendor certifications. Dograh AI ships all four natively in its self-hosted deployment, so regulated teams can satisfy each requirement without building custom tooling around it.
Frequently Asked Questions
What is the difference between a low-overhead voice AI framework and a closed platform like Vapi or Retell?
Low-overhead frameworks replace custom orchestration code with visual builders and pre-built integrations, while remaining self-hostable so data stays in your environment. Closed platforms like Vapi and Retell reduce integration work but introduce usage-based pricing that's difficult to model at scale, vendor lock-in, and data-sharing requirements that disqualify them from regulated industries.
Can I run a voice AI agent entirely on-premise with open source models?
Yes. A fully local stack is achievable using Whisper, Canary, or Voxtral for STT; Llama or Qwen for LLM; and Kokoro, Coqui, or Chatterbox for TTS. Dograh AI supports Docker-based self-hosted deployment with all these model options through a bring-your-own-model architecture.
How does Speech-to-Speech orchestration reduce latency in voice AI deployments?
S2S removes the sequential STT → text → LLM → text → TTS round-trip by keeping voice and reasoning in a shared runtime. This eliminates the 100–300ms API boundary overhead at each pipeline stage, with GPT-4o Realtime achieving audio responses as fast as 232ms.
Which deployment model works best for scaling contact centers?
Performance at scale depends on concurrent call handling capacity, geographic telephony infrastructure, and API key rotation to prevent rate-limit bottlenecks. Self-hosted OSS deployments give teams the most control over all three variables, including the ability to scale to infrastructure capacity without per-minute platform fees.
How do I maintain GDPR or HIPAA compliance when self-hosting a voice AI system?
Self-hosting eliminates vendor compliance certifications from the procurement process. Internal controls that remain your responsibility: encryption at rest and in transit, RBAC, data retention policies for recordings and transcripts, and audit logging. Dograh AI includes all of these out of the box.
What open source models can I use for STT, LLM, and TTS in a voice AI agent stack?
Main options by layer: Whisper, Canary, and Voxtral for STT; Llama and Qwen for LLM; Kokoro, Coqui, and Chatterbox for TTS. Not all platforms support all models, so the ability to connect your own locally hosted models is the most important factor to evaluate when choosing a platform.


