
Introduction
Adding headcount every time call volumes spike is a losing strategy. Hiring, training, supervising, and replacing agents costs more each cycle — and the math never improves.
According to ContactBabel's 2024 US Contact Center Decision-Makers' Guide, experienced agents earn $46,114 in mean annual salary alone, with benefits adding nearly 30% on top and recruiting costs averaging $4,700 per hire. Multiply that by 31% mean annual attrition, and the compounding cost of standing still becomes hard to ignore.
Voice automation promises a way out. But most contact centers discover, too late, that the platform they chose was built for demos — not for thousands of simultaneous calls under real production load.
This guide covers what scalability in voice automation actually means technically, what architecture makes it possible, how to evaluate platforms honestly, and how to measure results. If you're running thousands to hundreds of thousands of calls per month, this is where to start.
Key Takeaways
- Scaling voice automation requires infrastructure that handles concurrency, latency, and end-to-end task completion — not menus
- Legacy IVR breaks at volume: no natural speech, no multi-step tasks, no simultaneous LLM/STT/TTS concurrency
- Vendor rate limits silently cap concurrent calls — a ceiling most closed platforms don't advertise
- Self-hosted or private-cloud deployments remove that ceiling and eliminate HIPAA/GDPR vendor processing overhead
- Track five KPIs: automation rate, average handle time, cost per call, first contact resolution, and escalation quality
Why High-Volume Contact Centers Hit a Scalability Wall
The Compounding Cost Problem
When call volume doubles, a headcount-dependent contact center sees costs double too. Every additional agent requires hiring ($4,700 average cost per hire per SHRM), onboarding, supervision, and ongoing management — and with 31% mean annual attrition, you're perpetually refilling a leaking bucket.
ContactBabel's benchmark data puts the mean inbound cost per call at $6.91. That figure includes agent time, but fully-loaded costs stack additional layers: supervisor overhead, quality assurance, technology, and facilities. None of these scale favorably.
Why Legacy IVR and First-Generation Bots Fail
Traditional IVR operates on rigid decision trees. Callers who deviate from the expected path — different phrasing, accented speech, background noise — get dead ends. ContactBabel reports:
- 32% of telephony self-service calls zero out to a live agent
- 7.1% call abandonment rate across the industry
- Only 26% of self-service calls are fully resolved without agent involvement

That's a self-service system that fails nearly three-quarters of the callers it touches. First-generation chatbot-to-voice ports perform similarly — they can answer one-dimensional questions but collapse on multi-step tasks like verifying identity, pulling a CRM record, and scheduling a callback in a single interaction.
The Hidden Ceiling: Vendor Concurrency Limits
This is the bottleneck most articles skip entirely.
At scale, every voice call requires simultaneous STT transcription, LLM inference, and TTS synthesis — often within a sub-second window. Cloud-based AI providers enforce rate limits on these services. On shared multi-tenant platforms, one customer's volume spike affects everyone else's response latency.
Two consequences contact centers rarely anticipate:
- A platform rated for 500 concurrent calls may silently degrade at 300 when it hits a provider's API rate limit
- Vendors almost never disclose this ceiling during sales conversations
The architectural fix is API key rotation: distributing load across multiple provider keys so no single rate limit becomes a bottleneck. Dograh AI's BYOK (bring-your-own-keys) design supports this across STT, LLM, and TTS providers, letting organizations use their own accounts and rotate keys to manage concurrency at scale.
For teams that need to remove the ceiling entirely, self-hosted deployments bound concurrency only by compute capacity — not a vendor's shared infrastructure.
What "Scalable" Voice Automation Actually Means
Scalability in voice automation means serving 10×, 100×, or 1,000× the call volume with near-zero marginal cost per additional interaction — no degradation in latency or accuracy, no manual reconfiguration. Don't confuse this with "flexible" (easy to configure) or "automatable" (handles simple tasks). Those are different claims.
Inbound vs. Outbound Scalability
These two modes have different demands:
Inbound platforms must absorb sudden spikes without queue buildup. ContactBabel identifies the primary drivers as:
- Billing cycles and payment deadlines
- Product launches and service outages
- Seasonal surges and external events (weather, holidays)
Cloud deployments help here, but vendor concurrency limits can silently cap how much elasticity actually materializes.
Outbound requires launching large concurrent campaigns to thousands of contacts simultaneously. For outbound, the first 15 seconds determine whether the call proceeds or gets hung up. Interruption handling, pacing, context framing, and establishing legitimacy quickly are infrastructure and AI behavior problems — not script problems. Effective platforms encode these behaviors at the agent layer. Dograh AI has built specific handling for this: barge-in detection that stops TTS the moment a caller speaks, preserving clean conversation context through the handoff.
Concurrency Without Ceiling
At high volume, each simultaneous voice call requires:
- Live STT transcription (target: under 300ms per Deepgram's benchmarks)
- LLM inference for response generation
- TTS synthesis of the response
- Telephony transport back to the caller
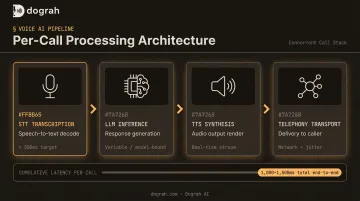
Research on human conversational turn-taking puts the average gap between speaker turns at 239 milliseconds in English. Automated systems typically land around 1,000–1,500ms before network delays — already perceptibly slower than human conversation.
That pipeline pressure is also why deployment model matters. Self-hosted and private-cloud deployments solve the concurrency ceiling structurally: the full stack runs on dedicated infrastructure, bounded by compute capacity rather than a vendor's shared rate limit.
The Cost-Quality Tradeoff at Scale
At high volume, TTS cost per minute becomes a significant line item. The emerging solution is hybrid voice: mixing pre-recorded human voice clips for predictable, high-frequency phrases (greetings, common confirmations) with TTS fallback for dynamic responses — all delivered in the same cloned voice.
Dograh AI's hybrid pre-recorded + TTS feature reports up to 3× cost reduction and 2× better outbound conversions using this approach. The pre-recorded segments sound more human because they are human; TTS handles the dynamic portions. The caller hears a seamless, consistent voice throughout.
The Technical Architecture That Enables Voice Automation at Scale
From Serial Pipelines to Speech-to-Speech
The traditional voice AI pipeline runs in sequence: STT → LLM → TTS, and each hop adds latency. STT alone can take 100–300ms; LLM inference and TTS synthesis stack on top of that; telephony transport adds more overhead still. End-to-end, traditional pipelines often land at 1.0–1.5 seconds before network delays are even counted.
ElevenLabs advises that conversational AI should target sub-second latency — and OpenAI's GPT-4o demonstrates what's achievable, responding to audio input in as little as 232ms, averaging 320ms.
Speech-to-Speech (S2S) orchestration collapses the serial pipeline into a direct audio-in / audio-out model, cutting out the intermediate conversion steps. Dograh AI ships S2S orchestration across the full stack using models including Gemini Flash Live and OpenAI GPT-Realtime-2, roughly halving end-to-end latency compared to traditional pipelines. At high volume, that latency reduction means less dead air, more natural turn-taking, and fewer callers dropping off before the interaction completes. That performance baseline matters just as much when those agents need to reach into live systems mid-call.
CRM and System Integration at Scale
Voice agents that can only converse, without looking up account records, checking order status, booking appointments, or updating CRM fields, aren't solving contact center problems. They're replacing one bottleneck with another.
At scale, integrations must be:
- Real-time — data fetched mid-conversation without perceptible delay
- Reliable — integration failures at scale mean hundreds of broken calls simultaneously
- Low-latency — a 2-second database lookup destroys the conversational experience
Webhook-based and tool-calling integrations allow a voice agent to fetch live data mid-conversation without adding perceptible delay. Dograh AI supports integration with Salesforce, HubSpot, Zendesk, ServiceNow, and 200+ apps via webhooks and API calls, with automatic CRM field updates triggered on call completion.
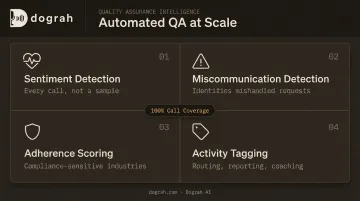
Automated QA at Scale
At high volume, human QA review becomes statistically meaningless — reviewing 2% of calls while 98% go unmonitored isn't quality assurance. Automated post-call analysis changes this:
- Sentiment detection across every call, not a sample
- Miscommunication detection to identify where agents misunderstand or mishandle requests
- Adherence scoring for compliance-sensitive industries
- Activity tagging for routing, reporting, and coaching workflows
Flagged calls feed directly into agent retraining and script refinement, creating a continuous improvement loop that tightens performance over time. Dograh AI's LoopTalk framework adds a pre-deployment layer: AI-to-AI testing that simulates real-world customer scenarios before calls go live, reducing the time needed to build dependable agents.
Key Capabilities to Evaluate in a Scalable Voice Automation Platform
Not all voice automation platforms are built to operate at the infrastructure layer a high-volume contact center requires. Here's a practical buyer's framework.
Deployment Flexibility and Data Sovereignty
For healthcare, fintech, legal, and government organizations, deployment model is a compliance requirement — not a preference.
Closed, multi-tenant cloud platforms route sensitive call data through third-party vendor infrastructure. That triggers HIPAA Business Associate Agreements, GDPR data processing agreements, and SOC 2 vendor reviews — each adding weeks or months to procurement.
Self-hosted or private-cloud deployment eliminates this overhead entirely. Data never leaves your infrastructure, so vendor compliance certifications aren't required.
The three deployment models to evaluate:
| Model | Best For | Trade-offs |
|---|---|---|
| Managed cloud | Fastest time to value, non-regulated industries | Vendor data policies, rate limits, per-minute fees |
| Self-hosted OSS | Maximum control, no platform fees, no vendor lock-in | Requires internal infrastructure management |
| Fully managed private cloud | Regulated industries needing sovereignty without ops overhead | Vendor manages the stack inside your own cloud environment |
Dograh AI offers all three. The self-hosted OSS version is available under BSD 2-Clause license on GitHub — an open-source alternative to closed platforms like Vapi and Retell, with auditable code and no platform fees. For organizations that need sovereignty without managing infrastructure themselves, Dograh's fully managed private cloud option deploys and operates the entire voice agent stack inside the customer's own cloud environment.
Language Coverage and Visual Workflow Building
For any contact center serving non-English-speaking callers, language coverage is non-negotiable. Dograh AI supports 70+ languages with accent handling across providers — not just translation, but genuine STT accuracy across accents and dialects.
Equally important is who can actually operate the platform day-to-day. Developer-only SDK platforms require engineering cycles for every change — a bottleneck that compounds as the contact center scales to new use cases. Dograh AI's drag-and-drop workflow builder changes that dynamic:
- Ops teams and RevOps build, test, and modify call flows without writing code
- RevOps owns copy and routing rules; engineering owns infrastructure and integrations
- Changes that take days on a code-heavy stack take minutes on a visual builder
Implementation Playbook: Rolling Out Voice Automation at Scale
Start With a Pilot, Define Success First
Identify the 2–3 highest-volume, most repetitive call types:
- Account status inquiries
- Appointment scheduling
- Outbound payment or appointment reminders
Define success criteria before the pilot — automation rate, CSAT delta, first-contact resolution — so expansion decisions are data-driven. ContactBabel reports that 24% of contact centers say over a quarter of inbound calls could be avoided with proactive outbound engagement. That's a measurable outbound automation opportunity from day one.
Human-AI Handoff: The Detail That Determines CSAT
Clean, context-complete escalation is what determines whether callers escalate smoothly or abandon the call entirely. When a call transfers to a human agent:
- Full transcript and call summary pass at the moment of transfer
- Intent classification tells the agent why the caller escalated
- Verification status confirms what identity checks already passed
- CRM fields pre-populate so the agent sees context, not a blank screen
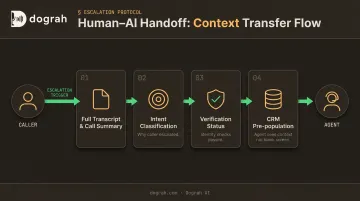
Dograh AI handles this via webhooks — triggering structured data transfer including intent, extracted slots, verification status, sentiment indicators, and last tool results at the moment of transfer. The caller never repeats themselves, and the agent starts with verified facts already in hand.
Change Management: Frame It Correctly
McKinsey's 2025 analysis of AI in contact centers found that AI automation may allow 40–50% fewer agents while handling 20–30% more calls, with some deployments achieving 50% reductions in cost per call.
Shared without context, those numbers read as a headcount threat — and agents who feel threatened work around the system rather than with it. The more accurate frame is this:
- AI absorbs tier-1 volume: status checks, reminders, verifications
- Human agents focus on complex conversations requiring judgment and empathy
- 31% mean annual attrition in contact centers is driven partly by repetitive, low-judgment work — removing those calls from agent queues reduces the burnout that drives turnover
That's a retention argument, not a replacement argument.
Measuring ROI and Performance at Scale
The Five KPIs That Matter
| KPI | Industry Benchmark | What to Track |
|---|---|---|
| Automation rate | 26% telephony self-service containment (ContactBabel) | % of calls fully resolved by AI with no human involvement |
| Average handle time | 442 sec service calls, 476 sec sales calls (ContactBabel) | AHT for AI-handled vs. escalated calls separately |
| Cost per call | $6.91 inbound, $5.97 outbound (ContactBabel) | Fully-loaded cost before and after automation |
| First contact resolution | 75% industry mean (ContactBabel) | Whether issues resolve in a single interaction |
| Escalation rate + quality | No universal benchmark | Are the right calls escalating, with full context? |

ROI Timeline and Cost-Per-Call Impact
ContactBabel pegs interaction analytics payback at 6–18 months in typical deployments. Three drivers consistently accelerate that payback:
- Outbound volume replacement: AI handles high-frequency, low-conversion call types (appointment reminders, payment nudges, lead qualification) at a fraction of per-call agent cost
- Hybrid pre-recorded + TTS: Replacing synthesized speech with pre-recorded human voice clips for common call openings cuts TTS cost while improving conversion — two improvements on a single metric
- Automated QA at 100% call coverage: Reduces compliance risk, shortens coaching cycles, and generates continuous improvement data without dedicated QA headcount
Frequently Asked Questions
What are the top voice AI solutions for scalable voice automation in high-volume contact centers?
Leading platforms include closed cloud solutions (Vapi, Retell, NICE CXone, Cognigy) and open-source, self-hostable alternatives like Dograh AI, which runs under a BSD 2-Clause license with full data sovereignty. The right choice depends on deployment model, compliance requirements, concurrency architecture, and whether the team needs no-code workflow building or developer-first APIs.
What software do most call centers use?
Most contact centers run a CCaaS layer (NICE CXone, Genesys Cloud CX, Amazon Connect, Five9, Twilio Flex), a CRM (Salesforce, HubSpot, Zendesk), and a workforce management tool. A voice AI automation layer sits on top — cloud-hosted or self-hosted depending on compliance requirements.
How does voice automation handle sudden spikes in call volume?
Cloud-based platforms can spin up additional agent instances on demand, but vendor concurrency limits are a hidden ceiling that can silently cap burst capacity. Platforms with API key rotation or self-hosted deployments handle spikes more reliably because they're not constrained by a shared provider rate limit.
What's the difference between cloud-hosted and self-hosted voice automation?
Cloud-hosted is faster to start but ties you to the vendor's infrastructure, data policies, and rate limits. Self-hosted gives the contact center full data sovereignty, no per-minute platform fees, and unlimited scale — removing the vendor compliance overhead that slows procurement in regulated industries.
How do you measure the ROI of voice automation in a high-volume contact center?
Track automation rate, cost per call, average handle time, first contact resolution, and escalation quality. ContactBabel benchmarks provide baseline comparisons ($6.91 inbound cost per call, 75% FCR, 26% self-service containment). Most organizations see measurable improvement within 6–12 months, with outbound automation often delivering faster payback.
Can voice automation handle complex, multi-step conversations or only simple queries?
Modern LLM-backed voice agents handle multi-turn, multi-step conversations: identity verification, account lookup, and appointment booking in a single call. Capability depends on the platform's integration depth, tool-calling architecture, and how well the agent is configured for the specific workflow.


